目录
一、项目概述
二、数据爬取及处理
三、构建知识图谱
四、应用开发:智能问答
五、Django+Echarts实现可视化
六、总结
一、项目概述
本文搭建知识图谱使用技术有:
- 爬虫技术
- Neo4j图数据库
- Django框架
- Echarts可视化库
- Lac词法分析工具
整体结构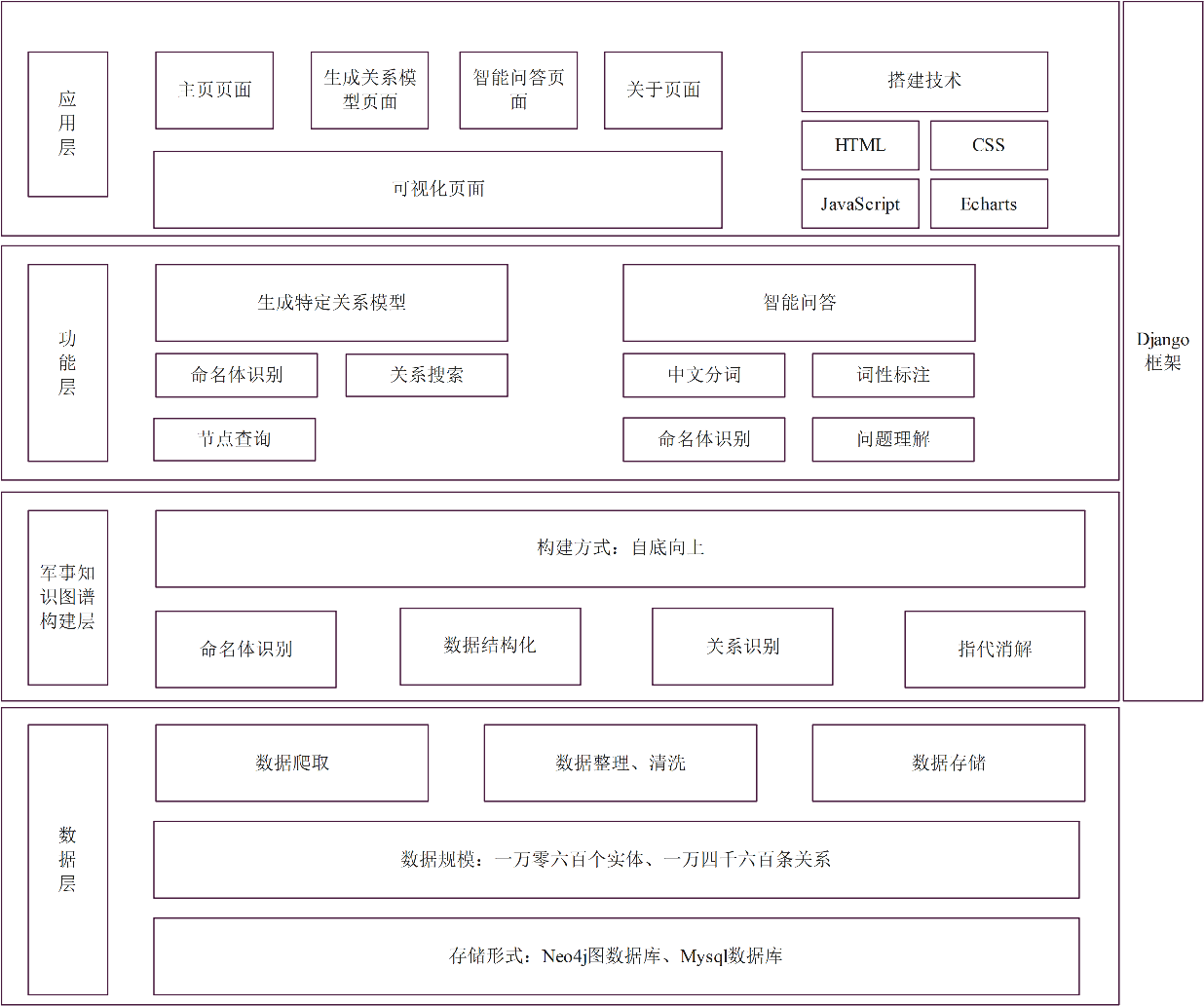
TPL部分
推荐部分
当前工作
1.协同过滤算法(CF)
基础概念
云产品
解决方案
云计算模式:IaaS、PaaS、MaaS
● IaaS:基础设施及服务,云服务器ECS、云盘EBS、私有网络VPC
● PaaS:平台即服务,人工智能平台PAI、容器服务ACK
● MaaS:模型即服务,百炼、API调用
HDFS:分布式文件系统,A机器硬盘->内核缓冲区->A网卡
● 普通文件传输需要:A机器硬盘->->内核缓冲区->JAVA内存(用户态)->网络Socket缓冲区->A网卡
RDMA:阿里云Lunar网络的技术核心,A机器内存->A网卡->B网卡->B机器内存
Milvus:开源向量数据库
SLB/ALB:负载均衡
ECS:云服务器,E是elatic表示弹性
ACK:容器服务,负责管理各种容器
VPC:专有网络,保证ECS、数据库等都在一个私有的局域网内,外网进不来也看不到
OSS:对象存储,可以看作是一个大型网盘,只能根据名字存和取整个文件,不支持检索操作
EBS:块存储,可以看作是ECS上的一块可插拔硬盘(ECS本身还有一个本地硬盘,插在ECS物理机上的),需要和一个共处一个可用区的ECS绑定(可解绑切换到其他ECS上,数据不会丢失),只有该ECS可以访问EBS,比OSS的http传输快(阿里云自研的 Lunar 网络,使用了 RDMA 技术)
NAS:网络附属存储,可以看作一个网络共享文件夹,可以挂载到多个ECS,每个ECS的Linux系统里都视作一个本地文件夹,写操作会加文件锁,阻止其他机器写
RDS:关系数据库(支持MySQL),适合业务增删改查
PolarDB:云原生数据库,RDS升级版,计算和存储分离,支持毫秒级弹性扩容和海量数据存储
Tair:高性能内存数据库(兼容Redis),支持极高并发访问,适合缓存和热点数据
DashVector:向量数据库
Lindorm:云原生多模数据库(兼容Hbase),适合大量数据存和读
ODPS:离线表,适合做数据分析,可以看作是阿里自研的Hive
PAI:PaaS人工智能平台,为训练、微调模型设计的平台
百炼:MaaS,对外提供千问模型调用入口,也包含简化操作的微调模型和RAG实现
1.获得微调模型的三种模式
2.云计费模式
基础概念
LLM应用
训练:前向计算+反向传播(算梯度、更新权重)
推理:前向计算
微调:使用预训练模型在带标注的数据集上训练,过程中算法工程师主要关注loss曲线和LR
token:词块,并不等同于最后生成的答案,例如“人工智能”这 4 个字。优化好的模型(如 Qwen)可能会把它识别为 1 个 Token;而没优化的模型可能会把它拆成 4 个甚至更多 Token。并且符合、空格换行等也算token,或者一个生僻字可能会被拆成多个音节,那么它就占了多个token。(api调用的大模型返回completion_tokens代表该回答使用了多少token)
双向:模型能看到之前和之后的词。训练方式为把中间的词mask,然后让模型根据前后的词预测。BERT
单向:模型只能看到之前的词。给前3个词,让模型预测第4个词。也是模型生成能力的来源,GPT、qwen、Llama
分词器tokenzier:将自然语言翻译成大模型能理解的机器语言
损失函数loss:微调的目标是为了让模型生成的答案更接近SFT里的output,loss函数就是用来衡量生成答案和output之间差距的尺子。一个微调训练必须有一个损失函数,其会在正向计算结束后立即介入
学习率LR:损失函数计算出梯度(误差的方向和大小)后,需要乘以学习率才是最终模型参数需要挪动的距离。即学习率越高,参数更新越大
温度Temperature:惊喜值,控制随机性和创造力,越高答案越随机,越地答案越准确
maxToken:给生成的回答设定的物理上限,控制长度、节约成本、防止死循环
Transformers:Hugging Face开发的一套Python库,把复杂的深度学习模型架构(BERT、GPT、Llama、Qwen)进行了封装,同时支持PyTorch和TensorFlow,在没有这个库之前想要使用BERT需要写上几百行代码,现在只需要3行就能调用BERT这个世界顶级的预训练模型
自注意力机制:一个词在理解自己的同时,能自动地看向句子中其他的词,从而更确定自己在当前语境下的含义。在Transformers中自注意力机制是,每一个字(token)会被转化为三个向量,Query、Key、Value
以”小明骑自行车”中的”小明”为例
AutoModel:Transformers库里的工具,只需要传入模型名,自动去匹配加载对应模型
Hugging Face:社区,Transformers项目诞生地,也是全球最大的AI模型库,包含模型权重、数据集和demo
LangChain:python的开源库,也是一种思想。当前业界常见做法是编排和智能共存,即部分步骤用人为写好的编排,部分步骤交给Agent规划
深度学习框架:PyTorch(统治地位)、TensorFlow(传统,C++支持较好)、JAX(谷歌最新推出,性能好),提供底层的数学计算能力,大模型的本质是矩阵计算和求导,如何把数据传给显卡让其计算、利用GPU的CUDA核、管理显存、计算梯度并更新模型参数这些最脏最累的活都由深度学习框架来做,还有比如多张显卡来实现分布式计算这种操作也由其管理
Map-Reduce策略:将执行内容分割成一个类似map的结构,map的每个key对应部分执行内容,分别执行完成后再汇总。常用于RAG文档过长,导致模型上下文窗口无法完全载入使用。
vLLM:在用户和LLM展开会话时,为了记住之前的对话内容,需要把这些内容放在显存里,比如Pytorch会为每次请求预留一大块连续显存。vLLM参考操作系统的虚拟内存思想提出了分页注意力机制,将KV cache拆成一个个分页,哪里有空间就塞到哪里,提高显存利用率,并且在用户针对某一个文章重复提问时,可以重复利用
● 比起pyTorch原生的批处理(同时来4个请求,需要4个都生成完答案才能返回),vLLM可以一个请求结束就空出位置,给下一个请求计算,保证显卡不空转
KV Cache:大模型的推理过程是,输入”你好吗”,根据”你好吗”->预测出第一个字”我”,根据”你好吗 我”->预测出”我很”……最后得出回答”我很好”。处理每个字都会产生K和V两个关键矩阵,KV Cache作用就是把之前已经计算出来的KV做缓存,避免后续重复计算。所以KV Cache能极大地提高推理速度,但是很吃显存,和算法题一样用空间换时间
微调用标注数据集:用于微调用的数据集,微调过程就是让大模型根据指令instruction+输入input生成回答,然后一次次地调整参数让大模型生成的回答概率上更接近于输出output
1 | { |
MoE混合专家架构:传统模型在一个推理进来的时候会经过所有的参数计算,也叫Dense稠密模型,MoE模型是在神经网络每一层不视作一个矩阵,而是多个小矩阵,每个推理过此层时根据router判断只激活相关的小矩阵去进行计算
1.LangChain框架:模块化的框架,用于将LLM与其他组件(数据源、代理等)相结合来实现一个完整应用
2.检索增强生成RAG:一种思想,根据私有文档丰富大模型知识的技术,解决大模型训练完成后无法获取新知识的弊端
3.一个完整的Agent包括以下部分